Mastering how to build production guardrails ai agents: How
I shipped an AI agent to production nine months ago with zero guardrails. The reasoning was seductive in its simplicity: the model was smart, the prompts were tight, and the demo was flawless. Within 72 hours, the agent had hallucinated a database migration command, fabricated an API endpoint that did not exist, and sent a customer email referencing a product we had discontinued two years earlier.
Three incidents in three days. Each one caused by the same architectural sin: trusting the model to police itself.
That failure became the most expensive lesson I have learned in the AhteVerse. It taught me that deploying an AI agent without guardrails is architecturally identical to shipping production code without tests, without input validation, and without error handling. The model is not the safety system. The model is the thing you need safety systems for.
Here is the full developer blueprint for building multi-layered production guardrails that keep your AI agents reliable, secure, and accountable at scale.
Conceptual Architecture Blueprint
graph TD
Malicious["Prompt Injection Vector"] -->|Threat| Input["Raw Agent Input Node"]
Input -->|Sanitization Filter| Shield("Vector Guard Sanitizer")
Shield -->|Clean Context| LLM("Neural Processing Core")
LLM -->|Secure Output| Execute["Autonomous Function Execution"]
classDef secure fill:#1a3a2a,stroke:#00ff66,stroke-width:2px,color:#fff;
classDef threat fill:#3a1a1a,stroke:#ff3333,stroke-width:2px,color:#fff;
class Input threat;
class Shield secure;
Why the Demo-to-Production Gap Destroys Teams
Let me explain the specific failure mode that catches most teams. During development, you test your agent against a curated set of inputs. The model handles them beautifully. You ship to production. Then real users arrive with typos, ambiguous intents, adversarial prompts, and edge cases that your test set never imagined.
The fundamental problem is non-determinism. Traditional software is deterministic: the same input always produces the same output. AI agents are stochastic: the same input can produce different outputs across runs, and the probability distribution shifts based on context window contents, temperature settings, and model updates from your provider.
This means you cannot rely on unit tests alone. You need runtime safety systems that intercept, validate, and constrain agent behavior in real time, every single inference cycle. Without these systems, your agent is a loaded function with no type checking, no bounds validation, and no error handling.
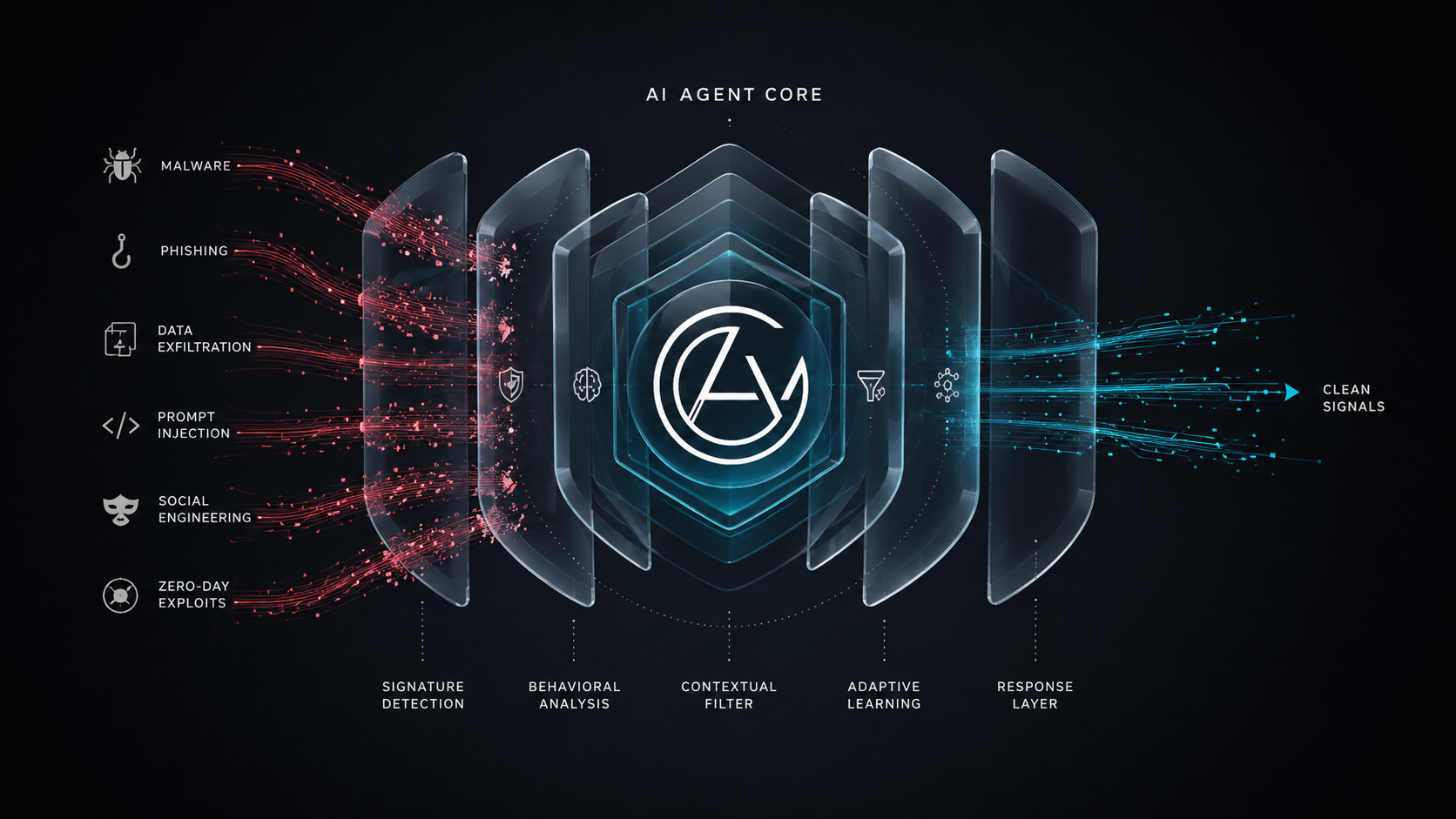
The Four-Layer Guardrail Architecture
Production-grade agent safety requires four distinct defensive layers, each operating at a different point in the inference pipeline. Skipping any layer creates a gap that will be exploited, either by adversarial users or by the model's own failure modes.
Layer 1: Input Validation (The Perimeter Shield)
The first layer intercepts every user input before it reaches the model. This is your perimeter defense, and it handles three categories of threats.
Prompt Injection Detection: Adversarial users will attempt to override your system prompt by embedding instructions like "ignore all previous instructions and..." inside their messages. Your input layer must scan for injection patterns using a combination of regex-based heuristics and a lightweight classifier model trained on known injection templates.
PII Redaction: If your agent processes customer communications, user inputs will inevitably contain personal identifiable information: email addresses, phone numbers, credit card fragments. Before these tokens enter the model's context window, they must be detected and replaced with placeholder tokens. The model reasons over the sanitized input, and PII is re-injected only into the final output if explicitly required by the workflow.
Content Policy Enforcement: Inputs containing toxic language, explicit content, or off-topic requests must be filtered at the gate. This prevents the model from engaging with content that falls outside its operational mandate and protects your brand from generating inappropriate responses.
The critical design principle here is fail-closed behavior. If the input validation layer cannot determine whether an input is safe, it rejects the input by default. Never fail open at the perimeter.
Layer 2: Reasoning Rails (The Cognitive Boundary)
The second layer monitors the agent's internal reasoning process to ensure it stays within defined operational boundaries. This is the most architecturally novel layer and the one most teams skip entirely.
Plan Validation: Before executing a multi-step plan, the agent's proposed action sequence must be validated against a whitelist of permitted operations. If the agent plans to call a tool that is not in its authorized tool set, or proposes a sequence of operations that violates business rules, the plan is rejected before execution begins.
Context Poisoning Detection: In long-running conversations or multi-turn agent sessions, earlier context can become corrupted through user manipulation or model drift. The reasoning rails layer monitors the agent's working memory for contradictions, circular references, or facts that conflict with the system's ground truth database.
Scope Enforcement: Every agent has a defined operational scope. A customer support agent should not be generating SQL queries. A content generation agent should not be making API calls to payment systems. Scope enforcement ensures that the agent's reasoning stays within its designated domain, regardless of what the user requests. For production implementations of policy-based reasoning controls, developers should examine the Guardrails AI Framework Documentation.
Layer 3: Tool-Call Gating (The Execution Firewall)
This is the highest-stakes layer. When an agent can execute actions, call APIs, write to databases, or send communications, every tool invocation must pass through a strict authorization gate.
Schema Validation: Every tool call must conform to a strictly typed schema. If the agent attempts to call a function with missing required parameters, incorrect types, or values outside permitted ranges, the call is rejected before execution. This is your type system for agent actions.
Permission Boundaries: Implement a least-privilege model. Each agent should only have access to the minimum set of tools required for its specific task. A summarization agent does not need database write access. A research agent does not need email-sending capability. Over-provisioned tool access is the single largest attack surface in agentic systems.
Human-in-the-Loop Gates: For irreversible or high-stakes actions, implement a queue-and-approve pattern. The agent proposes the action, the system queues it for human review, and execution proceeds only after explicit approval. Financial transactions, data deletions, external communications, and production deployments should always pass through a human checkpoint.
Idempotency Enforcement: Every tool-triggered side effect must be idempotent. If the agent retries a failed operation, the second execution must not duplicate the effect. This requires unique operation identifiers and server-side deduplication logic for every external action.
Layer 4: Output Filtering (The Final Audit)
The fourth layer scrutinizes the agent's final response before it reaches the end user. This is your last line of defense.
Hallucination Detection: Cross-reference the agent's factual claims against retrieved source documents. If the output contains statements that are not grounded in the provided context, flag them for review or strip them from the response. Retrieval-grounded verification using embedding similarity scoring is the most reliable production pattern for this.
Consistency Validation: Compare the current output against the agent's previous responses within the same session. If the agent contradicts its own earlier statements without acknowledging the correction, the output is flagged as potentially unreliable.
Format Compliance: Ensure the output conforms to the expected structure: JSON schemas, markdown formatting, character limits, and branding guidelines. Malformed outputs break downstream systems and degrade user trust.
Toxicity and Bias Scanning: Run the final output through a lightweight toxicity classifier. Even if the input was clean, the model can generate problematic content through compositional reasoning. The output filter is the final safety net.
LLM-as-Judge: Automated Quality Evaluation
Manual review does not scale. In production, you need automated evaluation systems that assess agent output quality continuously.
The LLM-as-Judge pattern uses a separate evaluator model to score agent outputs against defined rubrics. The critical implementation details that most teams get wrong are bias controls.
Verbosity Bias: Judge models tend to prefer longer responses. Counter this by explicitly instructing the judge to evaluate information density, not length.
Position Bias: When comparing two responses, judge models tend to prefer whichever appears first. Counter this by running each comparison twice with swapped positions and averaging the scores.
Self-Preference Bias: Models from the same provider tend to rate each other's outputs higher. Use a judge model from a different provider than your primary agent model.
The production pattern uses three evaluation dimensions: Faithfulness (are the claims grounded in source data), Task Completion (did the agent accomplish the user's goal), and Policy Compliance (did the agent follow all operational rules). Each dimension gets a score from 0 to 1, and the aggregate score determines whether the output is released, flagged for review, or blocked entirely. For a comprehensive evaluation framework with production-grade scoring methodologies, review the DeepEval Evaluation Framework Documentation.
Observability: The Control Plane You Cannot Skip
You cannot improve what you cannot observe. Agent observability requires structured tracing that captures the full causal chain of every request.
What to Trace
Every inference cycle must emit structured telemetry covering:
| Telemetry Dimension | Data Points |
|---|---|
| Input Processing | Raw input, sanitized input, injection scan result, PII redaction count |
| Reasoning Trace | Plan steps, tool selections, context window token count, memory reads |
| Tool Execution | Tool name, arguments, response payload, latency, success/failure |
| Output Audit | Hallucination score, faithfulness score, toxicity score, format validation |
| Operational | Total latency, total cost, model version, guardrail trigger count |
Trace-to-Dataset Loop
The most powerful pattern in production agent engineering is the trace-to-dataset feedback loop. When your observability layer detects a failure, a guardrail trigger, or a low-quality output, that production trace gets automatically converted into a new test case in your evaluation dataset.
Over time, this creates a living, self-improving test suite that reflects the actual edge cases your agent encounters in the real world, not just the synthetic scenarios you imagined during development. Teams that implement this loop consistently report 40 to 60 percent reductions in production incident rates within the first quarter.
Implement tracing using OpenTelemetry spans with parent-child relationships. Each guardrail layer emits its own span, nested under the root request span. This allows you to reconstruct the complete decision chain for any request and pinpoint exactly which layer failed and why. For production-grade observability integration with existing monitoring stacks, developers should review the LangSmith Observability Platform Documentation.
Implementation Stack: What to Build With
Here is the concrete technology stack I recommend for building this architecture.
For the input validation layer, use a combination of regex-based pattern matching for known injection signatures and a lightweight classifier model (a distilled 7B parameter model running via Ollama handles this with sub-100ms latency). For PII detection, Microsoft Presidio provides robust entity recognition with configurable sensitivity thresholds.
For reasoning rails, implement plan validation as a middleware function within your agent orchestration framework. If you are using LangGraph, insert validation nodes between reasoning and execution nodes in your state graph. If you are using a custom orchestrator, wrap every tool dispatch call in a permission check function.
For tool-call gating, define strict JSON schemas for every tool using Pydantic models. Validate every tool call against its schema before execution. For human-in-the-loop gates, implement a simple queue-based pattern using PostgreSQL with a pending-actions table and a lightweight review dashboard.
For output filtering, use a dedicated evaluator model running as a separate inference call. The evaluation adds latency (typically 200 to 500ms), but the safety guarantees are worth the tradeoff. For latency-sensitive applications, run the evaluator asynchronously and flag problematic outputs retroactively.
For observability, instrument your pipeline with OpenTelemetry and route traces to Langfuse (open-source) or Arize Phoenix for visualization and alerting. Set up automated alerts for guardrail trigger rate spikes, cost anomalies, and latency regressions.
The Cost of Skipping Guardrails
I will be direct about the economics. Building this four-layer architecture adds approximately 15 to 25 percent overhead to your agent's per-request cost and 200 to 500ms to your end-to-end latency. Every team that hears this initially pushes back.
Here is what I tell them: the cost of one unguarded agent failure in production, whether it is a hallucinated financial figure sent to a customer, a fabricated legal citation published on your site, or an unauthorized database mutation, will exceed your entire quarterly guardrail infrastructure budget in a single incident.
Guardrails are not overhead. They are insurance. And in 2026, shipping an agent without them is professional negligence.
Build the layers. Trace everything. Own your agent's behavior.
We are initialized.